OpenAI's o3 Model: Achieving Human-Level Performance on the ARC Benchmark
Auteur: Siu-Ho Fung
February 1, 2025
In the beginning of 2025, OpenAI released its groundbreaking "o3" model, representing a significant step toward Artificial General Intelligence (AGI). This model demonstrates unprecedented reasoning capabilities that approach human-level intelligence in specific domains. Unlike previous AI systems focused on narrow tasks, the o3 model shows the ability to generalize knowledge and solve novel problems-a key characteristic of AGI, the theoretical form of AI that can understand, learn, and apply intelligence across a wide range of tasks at human or superhuman levels. It's worth noting that the term AGI is often interpreted differently across the field, with varying definitions regarding the scope, capabilities, and benchmarks that constitute true general intelligence.
A Historic Moment for AI
Today marks a significant milestone for the AI community. OpenAI has announced the release of its new model, o3, which is considered the second iteration in the o1 series-an architecture known for extended reasoning capabilities.
This release is noteworthy because the o3 model has achieved human-level performance on the ARC Benchmark, a key indicator in the field of machine intelligence.
Why the ARC Benchmark Matters
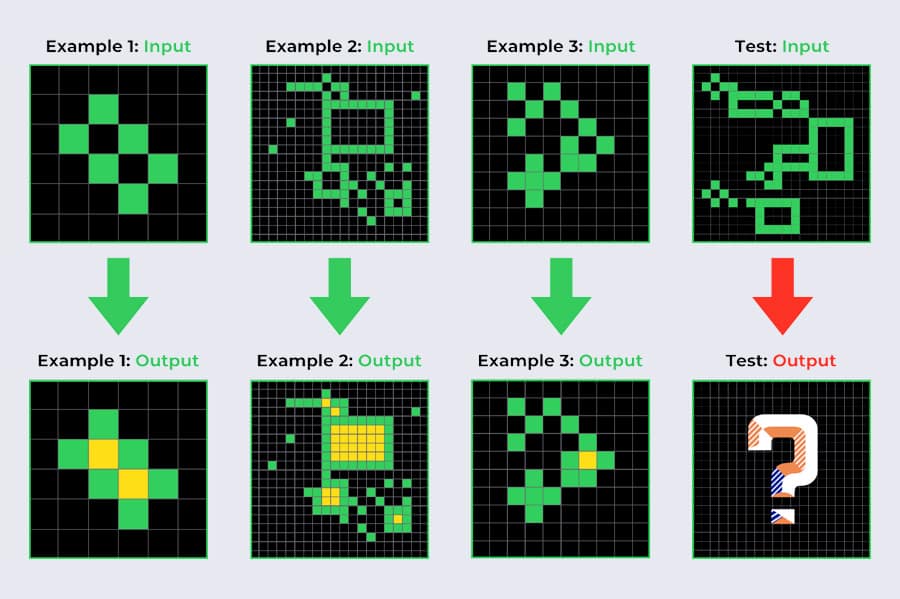
The ARC (Abstraction and Reasoning Corpus) Benchmark is widely regarded as a foundational test for evaluating general intelligence in AI systems. Unlike traditional benchmarks, ARC is resistant to memorization and focuses on core reasoning.
What Makes ARC Unique?
- Core Knowledge Only: The tasks require fundamental understanding-elementary physics, object recognition, and counting.
- No Repetition: Each problem is unique, testing the model's ability to learn on the fly.
- Human Benchmark: Tasks are easily solvable by humans, yet difficult for most AI models.
How ARC Works
Each ARC puzzle consists of:
- Input examples
- Output examples
- The AI must deduce the transformation rule and apply it to a new scenario.
While humans can intuitively solve these tasks, AI systems have historically struggled-until now.
Performance Breakthrough
OpenAI's o3 model achieved a 75.7% score on the semi-private ARC AGI benchmark, a massive leap from the previous best of around 5% by earlier frontier models.
This performance makes o3 the new state-of-the-art on the ARC leaderboard.
Model Variants: Low vs. High Tuning
Two versions of o3 were tested:
- Low-Tuned o3: Optimized for speed and cost efficiency; ideal for straightforward tasks.
- High-Tuned o3: Uses more computation for deeper reasoning; ideal for complex, multi-step problems.
It was the high-tuned version that achieved the breakthrough result.
Is This True AGI?
According to benchmark creators, this result marks a genuine breakthrough in adaptation and novelty, placing us in uncharted territory.
However, experts like François Chollet argue this is not yet AGI, as the model still fails on some simple tasks. Nonetheless, he acknowledges that this is a major milestone.
Reflections on AGI Definition
The term AGI (Artificial General Intelligence) has evolved. As we approach it, its definition becomes more nuanced:
- Some see AGI as equivalent to the capabilities of o1-level models.
- Others define AGI as superintelligence-surpassing all of humanity.
- OpenAI now uses a five-level framework to track reasoning progress, rather than a binary AGI/not-AGI label.
Compute Costs and Practical Constraints
While performance is impressive, compute costs remain high:
- High-Tuned o3 can cost up to $11,000 USD per task
- Even low-tuned variants can cost over $1,000 USD per task
Such costs are unsustainable for broad deployment, but efficiency will likely improve over time-just as we saw with TVs, phones, and other early tech.
Implications Across Benchmarks
Beyond ARC, o3 has also shown:
- 96.7% on competitive math benchmarks
- 87.7% on PhD-level science benchmarks
- 25% on the new Frontier Math Benchmark, a major improvement over prior models scoring only 2%
Looking Forward
OpenAI researcher Noam Brown suggests that the trajectory of o3 will continue to push boundaries. Meanwhile, CEO Sam Altman expects that by the end of 2025, systems will perform astonishing cognitive tasks that rival human intelligence in many domains.
Altman also highlights the importance of defining AGI in more granular terms, acknowledging the shifting landscape as capabilities evolve.
Final Thoughts
This release may not mark the arrival of AGI in the strictest sense, but it is undoubtedly a critical leap forward. As costs come down and understanding deepens, we are likely to see continued breakthroughs in reasoning, adaptability, and real-world application.
OpenAI invites safety researchers and developers to explore these models further as we enter a new chapter in artificial intelligence.

Schrijf in voor onze Nieuwsbrief
Hebt u vragen of hulp nodig? Wij helpen u graag.
Leverancier van betrouwbare serveroplossingen en opslag. Systeemintegratie van servers en opslag van fabrikanten zoals Supermicro, ASUS, NetApp, HPE, Dell, GIGABYTE, ASRock, Western Digital, Seagate, Micron, Chenbro, Toshiba. Wij leveren wereldwijd: Brussel, Parijs, Madrid, Rome, Amerika, Dubai en meer.
